- 前言
记录一下 Elastic-Job 学习过程, 运行Demo项目前请确保机器安装了 zookeeper, 并修改主类中的端口配置.
提取码: 8848
项目 GitHub 地址: elastic-job-demo
- 初识 Elastic-Job
Elastic - Job 是一款分布式定时任务框架, 它支持将一个任务拆分成多个独立的任务项, 由分布式的服务器分别执行某一个或几个分片项.
支持三种任务类型: Simple, DataFlow, Scrpit, 基本能覆盖大部分业务场景.
优点: 与Spring集成、支持分布式、支持集群、支持弹性扩容
缺点: 外部依赖 zookeeper、不支持动态添加任务
- Simple 类型定时任务
定时任务的简单实现, 只需要继承 SimpleJob 接口 实现 execute() 方法即可
package com.niu.elasticjob.job;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
/**
* Sample Job 实现类
*
* @author [nza]
* @version 1.0 2020/12/8
* @createTime 22:22
*/
public class MySampleJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
System.out.printf("我是分片项: %s, 总分片项: %s", context.getShardingItem(), context.getShardingTotalCount());
System.out.println();
}
}
- DataFlow 类型定时任务
该类型用于处理流式任务, 分为数据抓取和数据处理两步, 适用于不间歇的数据处理
如下图:
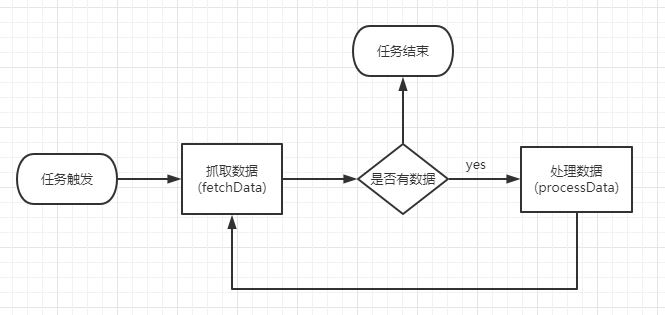
需要继承 DataflowJob 接口, 实现下列方法
List fetchData(ShardingContext context) : 抓取数据void processData(ShardingContext context, List data): 处理数据package com.niu.elasticjob.job;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import com.niu.elasticjob.model.Order;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* Dataflow 任务实现类
*
* 任务触发 -> 抓取 -> 处理
* 抓取 -> 处理 往复循环 直到抓取不到数据
*
* @author [nza]
* @version 1.0 2020/12/13
* @createTime 19:46
*/
public class MyDataFlowJob implements DataflowJob {
/**
* 模拟订单
*/
private static List mockOrders = new ArrayList<>();
static {
// 模拟100个订单
for (int i = 0; i < 100; i++) {
Order order = new Order();
order.setOrderId(i + 1);
order.setStatus(0);
mockOrders.add(order);
}
}
/**
* 抓取数据
*
* @param context 上下文
* @return 任务列表
*/
@Override
public List fetchData(ShardingContext context) {
List orderList = mockOrders.stream().filter(order -> canFetch(order, context))
.collect(Collectors.toList());
List res = null;
if (!orderList.isEmpty()) {
res = orderList.subList(0, 10);
}
// 休眠方便调试
sleep();
System.out.printf("我是分片项: %s, 抓取到数据: %s, 时间: %s", context.getShardingItem(), res,
LocalDateTime.now());
System.out.println();
return res;
}
/**
* 休眠3s
*/
private void sleep() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 是否满足抓取规则
* 订单号 % 分片总数 == 当前分片项
*
* @param order 订单
* @return boolean
*/
private boolean canFetch(Order order, ShardingContext context) {
return order.getStatus() == 0 && (order.getOrderId() % context.getShardingTotalCount() == context.getShardingItem());
}
/**
* 处理数据
*
* @param context 上下文
* @param list 任务列表
*/
@Override
public void processData(ShardingContext context, List list) {
list.forEach(order -> order.setStatus(1));
sleep();
System.out.printf("我是分片项: %s, 处理数据: %s, 时间: %s", context.getShardingItem(), list,
LocalDateTime.now());
}
}
- Script 类型定时任务
脚本作业, 用于执行脚本类型作业, 只需要书写脚本文件, 做简单配置即可。
以 cmd 脚本为例, 先编写一个脚本文件
test.cmd
echo 我是cmd脚本, 我的作业信息是: %1, %2, %3, %4, %5, %6配置App主类
/**
* 配置 Script JOB
* 1. job创建核心配置
* 2. job类型配置
* 3. job根配置(Lite)
*
* @return {@link LiteJobConfiguration}
*/
public static LiteJobConfiguration configurationScrpit() {
// 脚本文件地址(注意修改为本机地址)
String scriptFile = "E:\\code\\elastic-job-demo\\test.cmd";
// job创建核心配置
JobCoreConfiguration jcc = JobCoreConfiguration
.newBuilder("MyScriptJob", "0/10 * * * * ?", 2)
.build();
// 配置脚本任务
JobTypeConfiguration jtc = new ScriptJobConfiguration(jcc, scriptFile);
// job根配置(Lite)
return LiteJobConfiguration
.newBuilder(jtc)
.overwrite(true)
.build();
}
修改主函数
public static void main(String[] args) {
System.out.println("Hello!");
new JobScheduler(zkCenter(), configurationScrpit()).init();
}以上就是 Elastic-Job 三种任务类型的简单介绍, 可以根据实际业务场景选择运用.
end ~